2019-01-02T13:46:28.000Z
Java简单爬虫
思路
我打算爬取的网站是 Readhub,是一个新闻类的聚合资讯网站。每一篇新闻的页面,除了有新闻标题以及简单的新闻概要之外,还有类似的新闻集合。那么我要爬取的就是新闻标题、新闻概要以及类似的新闻。
那么一个简单的流程就出现了:
- 设置一个种子地址,作为爬虫的入口 startUrl;设置一个队列,用来存放待爬取的地址 newsQueue;设置最大的爬取数 maximumUrl;设置一个用于记录已经访问过的地址的集合 visted;设置一个用于保存新闻的数组 results;
- 将种子地址添加到队列里面;
- 在队列为空且计数已经超过 maximumUrl 之前,从队列中拉取一个目标地址进行访问,获取新闻标题、新闻概要以及额外的新闻集合
- 遍历额外的新闻集合,如果该新闻地址未曾出现在 visted,就添加到 visted 和 newsQueue
- 输出 results 里面的新闻
第三方包
- commons-io
- org.jsoup
- org.json(如果需要解析json)
jsoup 快速入门
代码及注释
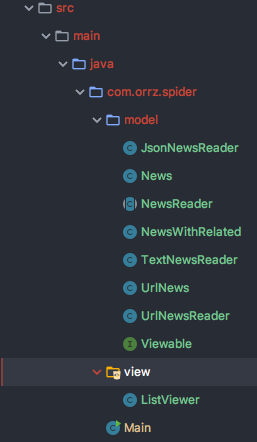
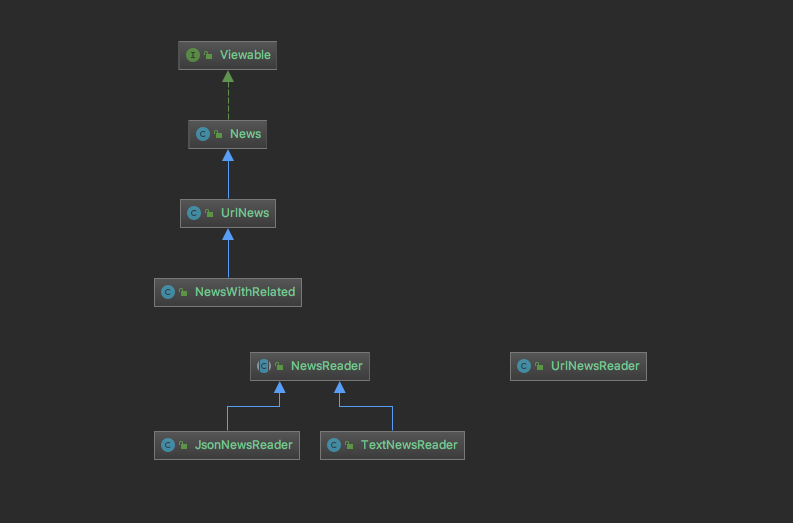
先从 model 包开始,包内存放的包括有 News类及其继承类、NewsReader及其继承类 、 urlNewsReader 类 和 Viewable接口。其中 News 父类继承了 Viewable接口。
News 类 其实是对新闻内容的抽象,里面有 title 和 content,而 UrlNews 还会额外多出 url。所有的 News 的 display 方法正式对 Viewable 接口的具体实现。
Viewable
package com.orrz.spider.model;
public interface Viewable {
// 只有一个未实现的方法 display
void display();
}News
package com.orrz.spider.model;
public class News implements Viewable {
private String title;
private String content;
public News(String title, String content) {
this.title = title;
this.content = content;
}
// getter
public String getTitle() {
return title;
}
public String getContent() {
return content;
}
// 实现 display 方法
@Override
public void display() {
System.out.println("--------------------------------------");
System.out.println("|Title| " + this.title);
System.out.println("|Content| " + this.content);
}
}UrlNews
package com.orrz.spider.model;
public class UrlNews extends News {
private String Url;
public UrlNews(String url, String title, String content) {
super(title, content);
this.Url = url;
}
public String getUrl() {
return Url;
}
@Override
public void display() {
super.display();
System.out.println("|Url| " + this.getUrl());
}
}UrlNews 继承自 News,增添了一个静态变量 Url
NewsWithRelated
package com.orrz.spider.model;
import java.util.HashMap;
import java.util.Map;
public class NewsWithRelated extends UrlNews {
// relateds 是一个 哈希表,用于存放类似的新闻列表
private HashMap<String, String> relateds = new HashMap<String, String>();
public NewsWithRelated(String url, String title, String content) {
super(url, title, content);
}
// 哈希表存的是新闻的标题和地址
public void addRelated(String title, String url) {
this.relateds.put(title, url);
}
public HashMap<String, String> getRelateds() {
return relateds;
}
// 这里的 display 在调用 父类的 display 之外,还输出哈希表的所有关联新闻
@Override
public void display() {
super.display();
System.out.println("|Related| ");
for (Map.Entry<String, String> Entry : this.relateds.entrySet()) {
System.out.println(Entry.getKey());
System.out.println(Entry.getValue());
}
}
}NewsReader
package com.orrz.spider.model;
import java.io.File;
public abstract class NewsReader {
protected File file;
public NewsReader(File file) {
this.file = file;
}
public abstract News read();
}NewsReader 是一个抽象类,内含抽象方法 read,对于不同的继承类可以有不同的 read 方法。
JsonNewsReader
package com.orrz.spider.model;
import org.apache.commons.io.FileUtils;
import org.json.JSONException;
import org.json.JSONObject;
import java.io.File;
import java.io.IOException;
public class JsonNewsReader extends NewsReader {
public JsonNewsReader(File file) {
super(file);
}
@Override
public News read() {
News news = null;
try {
String jsonString = FileUtils.readFileToString(file, "UTF-8"); // 读取文件
JSONObject jsonObject = new JSONObject(jsonString); // 创建 jsonObject 对象,然后就可以调用内置方法来获取指定字段
String title = jsonObject.getString("title");
String content = jsonObject.getString("content");
news = new News(title, content); // 构造 News 对象
} catch (IOException e) {
System.out.println("新闻读取出错"); // 这里抛出IO错误
} catch (JSONException e) {
System.out.println("json解析错误"); // 这里抛出 json的错误
}
return news;
}
}TextNewsReader
package com.orrz.spider.model;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.File;
public class TextNewsReader extends NewsReader {
public TextNewsReader(File file) {
super(file);
}
@Override
public News read() {
News news = null;
try {
BufferedReader reader = new BufferedReader(new FileReader(file));
String title = reader.readLine();
reader.readLine();
String content = reader.readLine();
news = new News(title, content);
} catch (java.io.IOException e) {
System.out.println("新闻读取出错");
}
return news;
}
}TextNewsReader 跟 JsonNewsReader 的实现类似,思路就是从文件中获取到 title 和 content 的字段来组成 News类对象,如果出现错误就抛出。
UrlNewsReader
package com.orrz.spider.model;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class UrlNewsReader {
public static NewsWithRelated read(String url) throws IOException {
// JSOUP 解析页面
Document doc = Jsoup.connect(url).get();
Elements titleElements = doc.select("title"); // 这里获取到的是标签名为 title 的 element 集合
String title = titleElements.first().text(); // 取第一个的文本内容
String content = doc.select("[class~=^summary]").text(); // 这里一般情况下输入的应该是 css类名选择器,但 Jsoup 提供了可以用正则来匹配。 由于 readhub网中不同的新闻里面的css类名也不同,所以只能用正则匹配上关键部分。 写法: 属性名~=正则表达式
NewsWithRelated news = new NewsWithRelated(url, title, content); // 新建一个NewsWithRelated对象,里面除了包含一条新闻以外还能存与之相关联的其他新闻 url 和 title
Elements reatledElements = doc.select("[class~=^timeline__item]"); // 这里要匹配的内容应该要事先对网站进行分析后得到的,通过查看浏览器的开发者工具来查找
// 遍历添加
for (Element element : reatledElements) {
String relatedTitle = element.select("[class~=^content-item]").text();
Elements children = element.children();
// 这里用到了 absUrl 方法,从 url属性获取绝对 url
// 如果属性值已经是绝对的,并且它成功解析为 url,就直接返回
// 否则就会被视为相对地址,自动填补
String relatedUrl = children.get(3).child(0).absUrl("href");
news.addRelated(relatedTitle, relatedUrl);
}
return news;
}
}为什么 UrlNewsReader 不继承 NewsReader ? 因为 UrlNewsReader 不需要解析文件,不存在需要解析 file的需求。
ListViewer
package com.orrz.spider.view;
import com.orrz.spider.model.Viewable;
import java.util.ArrayList;
public class ListViewer {
private ArrayList<Viewable> viewableList;
public ListViewer(ArrayList<Viewable> viewableList) {
this.viewableList = viewableList;
}
public void display() {
for (Viewable viewableItem : viewableList) {
System.out.println("------------------------------------");
viewableItem.display();
}
}
}ListViewer 比较简单,就是一个存放 实现了 Viewable 接口的对象的数组。这里的实现可以理解为 多态 的运用。
Main
package com.orrz.spider;
import com.orrz.spider.model.NewsWithRelated;
import com.orrz.spider.model.UrlNewsReader;
import com.orrz.spider.model.Viewable;
import com.orrz.spider.view.ListViewer;
import java.io.IOException;
import java.util.*;
public class Main {
static final int maximumUrl = 10;
public static void main(String[] args) throws IOException {
long startTime = System.currentTimeMillis();
// 广度优先搜搜
Queue<NewsWithRelated> newsQueue = new LinkedList<NewsWithRelated>();
String startUrl = "https://readhub.me/topic/5bMmlAm75lD"; // 起始地址
NewsWithRelated startNews = UrlNewsReader.read(startUrl); // 起始新闻 NewsWithRelated 对象是一个完整的 url新闻对象,因为里面还包含了其他的关联新闻
int count = 0;
Set<String> visited = new HashSet<String>();
visited.add(startUrl);
newsQueue.add(startNews);
ArrayList<Viewable> results = new ArrayList<Viewable>();
// 开始爬取
while (!newsQueue.isEmpty() && count <= maximumUrl) {
NewsWithRelated current = newsQueue.poll();
results.add(current);
count += 1;
// 遍历关联新闻并进行解析,如果还没有访问过就添加到 newsQueue 和 visted
for (Map.Entry<String, String> entry : current.getRelateds().entrySet()) {
String url = entry.getValue();
NewsWithRelated next = UrlNewsReader.read(url);
if (!visited.contains(url)) {
newsQueue.add(next);
visited.add(url);
}
}
}
long endTime = System.currentTimeMillis();
// 将爬取到的结果统一展示
new ListViewer(results).display();
System.out.println("程序运行时间: " + (endTime - startTime) + "ms");
}
}总结
设计这个小项目的重点在于:
- 如何精确地抽象对象 和 设计对象要实现怎样的功能?有什么属性和行文
- 选择合适的数据结构
- 我们要实现的功能是否已经有第三方包实现了?我们如果使用第三方包
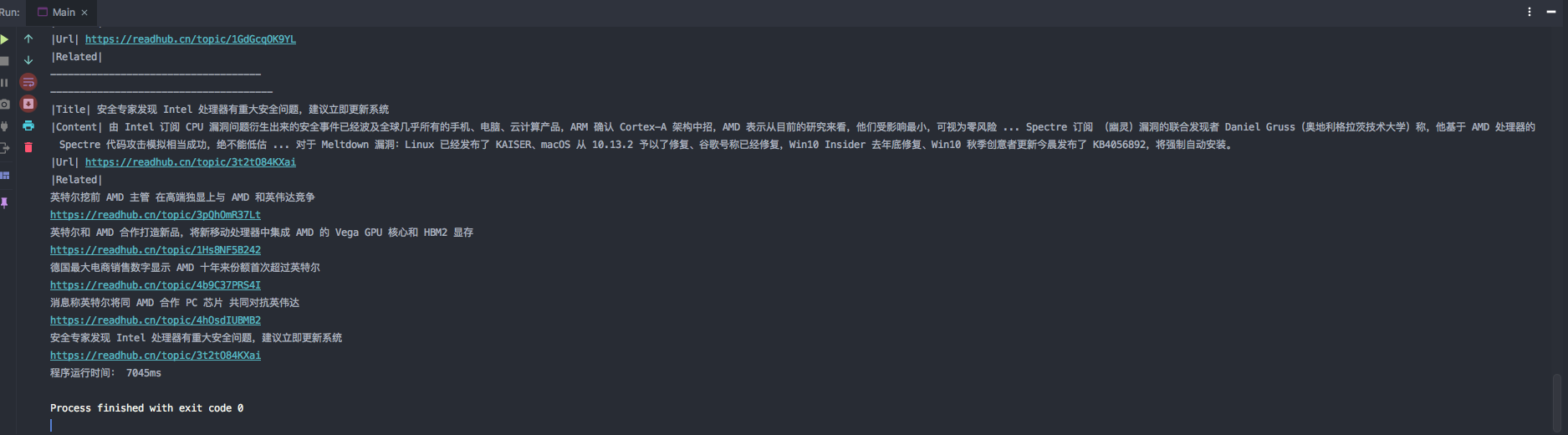
附上效果图: